At PEAK6, much like most businesses these days, our technology platform is the basis for how the business operates. In our case, it’s an equity options trading business. If the tech platform is down or otherwise unavailable, we don’t trade – the cause and effect is painfully direct. For that reason, we’re always looking to both improve the stability of our tech infrastructure and come up with new and better ways to recover quickly in the unlikely event of a major disruption to one of our datacenters that would require us to go into disaster recovery. In the trading world, minutes matter (and sometimes nanoseconds too, but that’s another topic for another day!), so having a disaster recovery plan that gets us back up and into the market as quickly as possible can be extremely valuable.
Now, when talking about recovering the entire PEAK6 trading platform to an alternate data center, we’re talking about a platform made up of hundreds of applications. Luckily, most of our in-house apps have been designed from the ground up to fail-over between our two Chicago datacenters seamlessly. Or, in the case of industry standard datastores like etcd, MongoDB, or Zookeeper, cluster member failure and distributed state are handled quite well natively in the application. However, we’re inevitably left with a hodgepodge of critical applications that don’t distribute their state well and can’t seamlessly fail-over from one datacenter to another – a lot of them could be classified as “legacy”. These apps present a significant challenge for a disaster recovery scenario. Going into disaster recovery mode and having 95% of our apps fail-over with no manual effort is great, but those missing 5% of applications might be critical to our trading operations and take hours to restore from backups or get back online, and that simply isn’t acceptable. Now, couldn’t we just bolt on some application-level HA onto these apps? Lehman’s 2nd Law would suggest that it’s going to be an uphill battle of increasing complexity‚Ķ

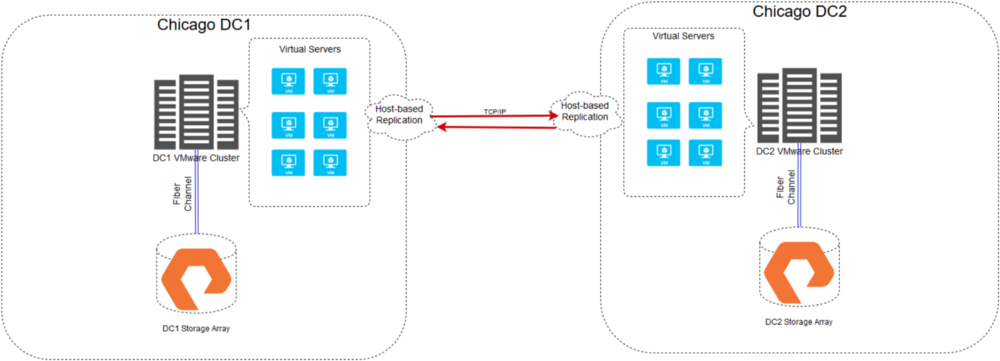
We’d much rather solve this problem at the storage layer – keep the HA complexity invisible to the legacy application while still distributing its state geographically. In the past, we’ve accomplished this with traditional host-based replication solutions for virtual environments (Zerto, Veeam, VMware replication, etc.). These host-based replication suites work well, but they still leave something to be desired – valuable minutes and even hours go by during a DR situation where engineers are logging in and clicking the magic “fail-over buttons, or worse yet, dealing with other crises before they even have a chance to initiate fail-overs for the legacy systems. Here’s what our traditional VMware environments look like across our two Chicago area datacenters when using host-based replication:
So, with that in mind, we were thrilled to hear last year that our favorite storage partner, Pure Storage, released the ActiveCluster solution. Here was a solution that offered synchronous bi-directional replication built-in to the arrays that we already had at each of our datacenters. It certainly looked like a great opportunity to take another look at a concept in the VMware world called a “Metro Storage Cluster.” In a Metro Storage cluster, a single, “stretched” VMware cluster takes advantage of the synchronously replicated LUN that appears to it as a single disk. The cluster spans both datacenters and uses VMware HA (or fault tolerance) to automatically get servers back up and running in the event of an outage to one location.
To be clear, a Metro Storage Cluster is not necessarily a new concept – they’ve been possible for quite a few years, primarily by use of replication appliances built by storage vendors with 3-letter names. However, we’d never really been keen on the concept due to the additional licensing, complexity, and significant performance penalties that these replication appliances bring with them. There were other critical questions to be answered in any cross-datacenter VMware cluster, too: how do we prevent split-brain and mediate tie-breaker scenarios? Will this cross-datacenter storage traffic crush our WAN circuit with its bandwidth usage? How quickly do the arrays handle path fail-over?
Through our testing with a VMware Metro Cluster built on top of Pure’s ActiveCluster, we were extremely pleased with the answers we found to these scary questions. 8k write IOPS to the ActiveCluster LUNs maintain a sub 3ms latency end-to-end (though it certainly helps to have a 150¬µs circuit‚Ķ). As for the split brain fear we had? That question was quickly put to rest, too. Pure bundles its ActiveCluster technology with the option of a “Cloud Mediator.” When dealing with any cluster that shares storage resources, there of course needs to be some method of determining which member takes control of write operations in the event of a network partition event. This isn’t unique to ActiveCluster but more of a logical reality that must be solved with a quorum, or, some 3rd member that lives apart from the other 2 and can settle any discrepancies about who is in control. This is where most vendors request that you run an extra virtual appliance or piece of software at a 3rd site that acts as a witness to the two arrays and provides quorum. Not the case with ActiveCluster! In a very modern and cloudy method, Pure takes care of this issue for us (for free) with the Pure1 Cloud Mediator, a witness in Pure’s cloud does the job just fine and we don’t have to worry about.
And what about the concerns over WAN bandwidth utilization? Ping ponging our storage traffic across the WAN could certainly lead to A Bad Time‚Ñ¢ if we really hit it hard, and our Network team was rightfully concerned when we first started our investigation. This is where, again, the Pure ActiveCluster has a great solution that I haven’t seen in most other vendors – because the synchronously replicated LUN is read-write in both locations, Pure allows you to configure a “Preferred array” for each host, thus forcing its storage traffic to the closest available array rather than traversing the WAN! Obviously, write ops still end up getting replicated across datacenters, but for read operations, ActiveCluster keeps them close to home and saves us from A Bad Time‚Ñ¢ on WAN utilization.
Here’s what our Metro cluster looks like now – whitepapers typically refer to this as a “uniform” setup:
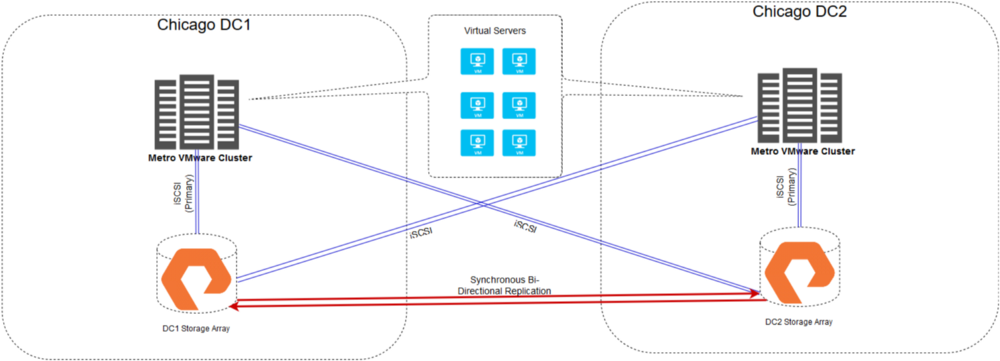
Virtual servers in the Metro Cluster no longer really “exist” in a single datacenter, but sort of “straddle” each datacenter at the same time. In the event that we lose connectivity to an entire datacenter or storage array, VMware HA kicks in and reboots the server at the healthy location in less than 2 minutes. And if 2 minutes is too long? Fault tolerant VMs can be created that straddle both datacenters and can fail-over between locations in a sub-second timeframe without reboot – this type of setup has me jokingly referring to these as Shroedinger’s servers üòä Fault tolerant VMs bring their own set of limitations though, so we rarely end up using them unless it really fits the bill (lack of RDM support, lack of vMotion, and no CPU hot plug, to name just a few of the limitations).
Solutions like our Metro Cluster allow us to extend the longevity of our application systems without increasing their cost or complexity. This is especially important to our business as it makes it easier for us to balance our investment in innovation alongside maintenance and modernization. So, as I said earlier, we’re happy to use natively distributed systems when they exist – modern systems like Kafka, Redis, Kubernetes, and others do a fine job of replicating state to other geographic locations. But, when the situations calls for it, the Metro Cluster on top of Pure’s ActiveCluster is a great, easy solution for drag and drop protection of workloads!
If you’re interested in hearing more about what we’re doing at PEAK6 or how you’d be able to join in, head over to our careers page. We’re always looking for curious, talented engineers who want to get their hands dirty both on-prem and in the cloud.